Granica Crunch optimizes cloud data lake storage costs via advanced compression algorithms which persist data as efficiently as possible, paired with real-time decompression upon access. Monthly savings are yours to use as you wish, whether for investing in strategic AI initiatives or simply applying straight to the bottom line. Crunch is optimized for multi-modal training files and other high volume data sets.
Losslessly compress petabyte-scale training data sets in your cloud data lake buckets, and maintain fast read access.
Losslessly compress and replicate files across regions for efficient compliance, recovery, and analytics uses.
Intelligently batch and cache data access operations to minimize the number of paid GETs and PUTs for read and write-intensive applications.
Pay Granica a percentage of your actual savings - if no savings then no bill. Move fast by eliminating financial risk.
Data types supported
Granica Chronicle AI supports any and all file types in your data lake.

Clickstream/Logs

Tabular
LiDAR
Image
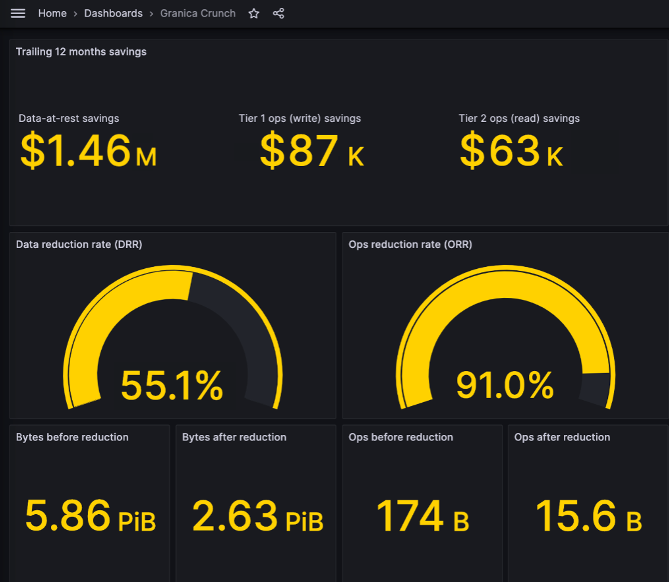
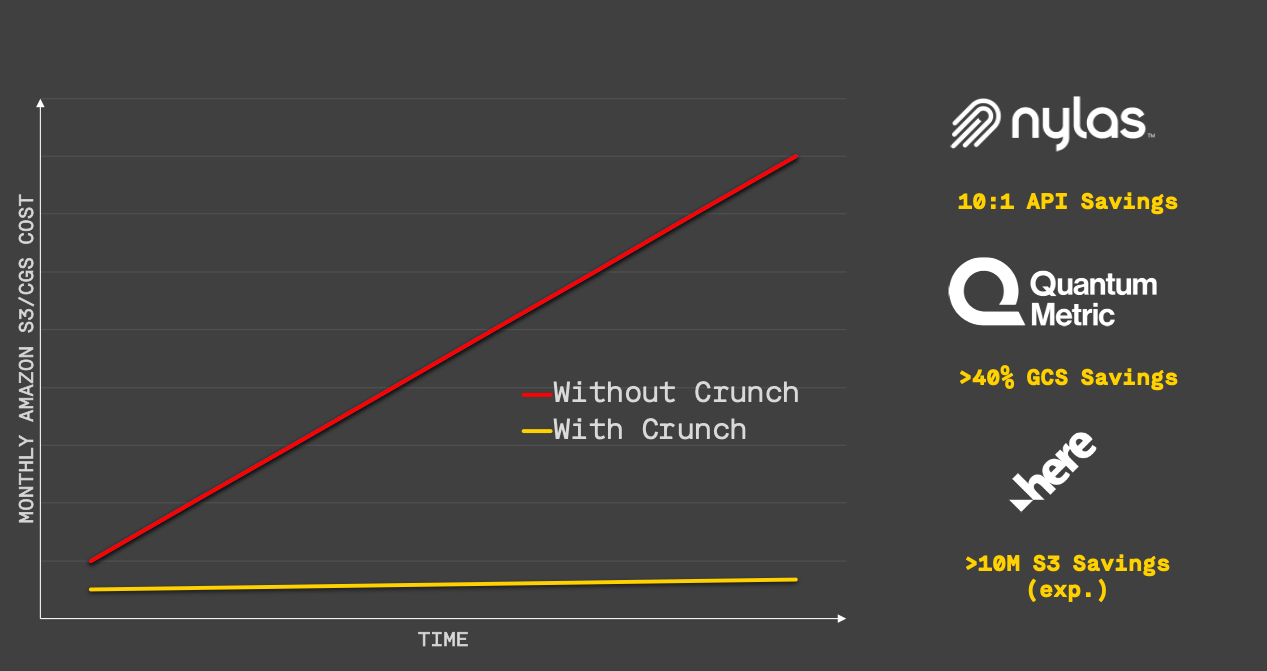
Reduce your unit economics cost to store data while avoiding the performance, availability, and highly variable read cost penalties associated with tiering and archival. Capture recurring savings relative to your native baseline each and every month, not just one-time. 10 petabytes of data typically translates into >$1.3M per year of cash savings, scaling as your data grows.
g ~/ granica deploy
Success!
g ~/
 Granica Named a 2023 Gartner® Cool Vendor
Granica Named a 2023 Gartner® Cool Vendor